24 Descriptive statistics
Descriptive statistics are numbers that summarise key aspects of a given dataset. These statistics often form integral parts of particular visualisations (Chapter 23); for example, the median and interquartile range are two important statistics in box-and-whisker plots. In this chapter we will discuss various kinds of descriptive statistics and their applications.
24.1 Single variables
In the following we will consider the task of summarising the distance variable in the following dataset:
Here is a histogram illustrating the variable’s distribution (see Chapter 23 for an introduction to histograms):
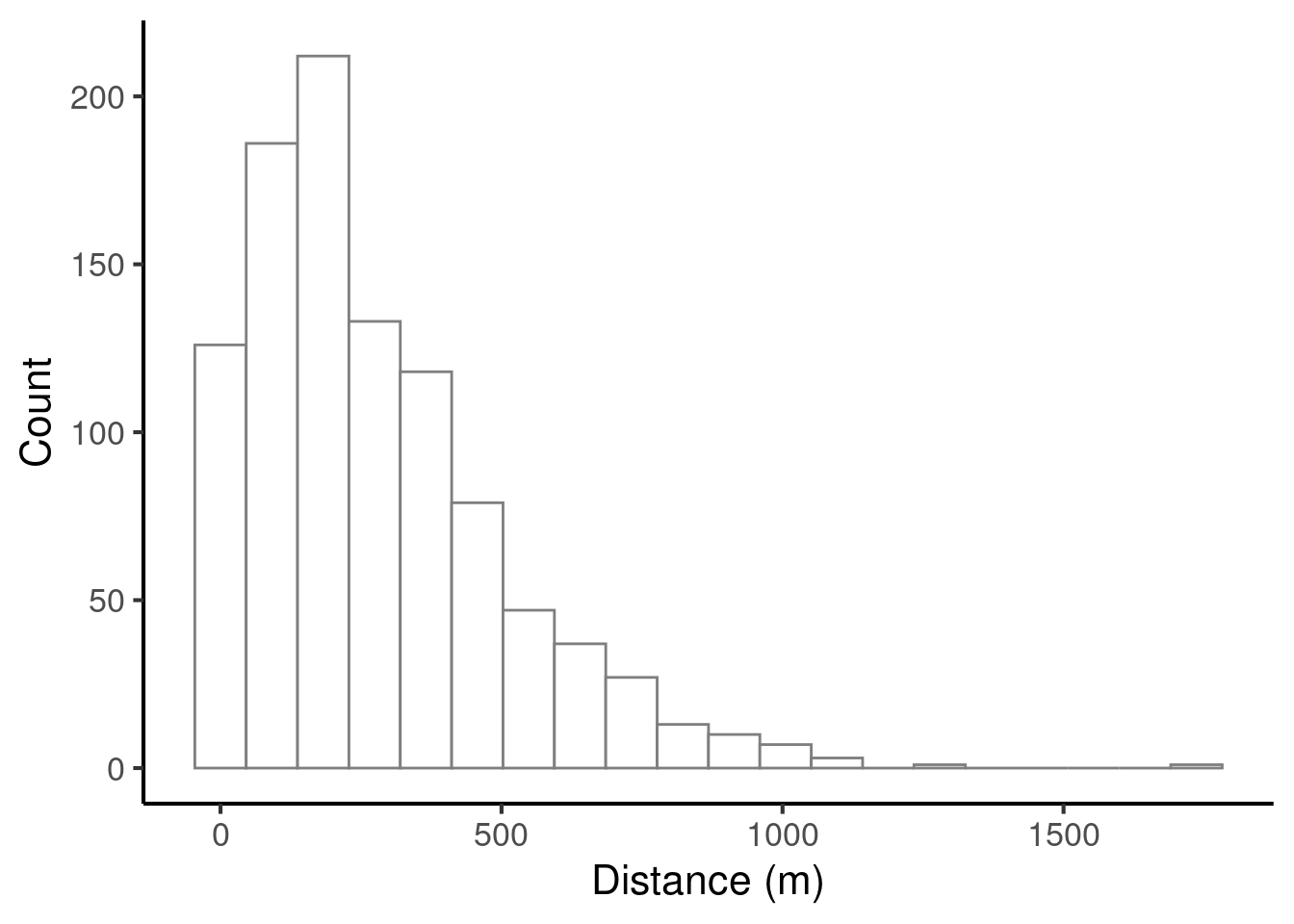
We will now consider various descriptive statistics that can be computed for this variable.
24.1.1 Centrality
‘Centrality’ statistics describe the location of a dataset’s centre. There are three classic centrality statistics: the mean (also known as the ‘average’), the median, and the mode.
24.1.1.1 Mean
We compute the mean of \(N\) datapoints by summing them together and dividing by \(N\). In mathematical notation, we can write the following:
\[ \textrm{mean}(x_1, x_2, \ldots, x_N) = \frac{x_1 + x_2 + \ldots + x_N}{N} = \frac{1}{N}\sum_{i=1}^N{x_i} \]
For example, the mean of 6.47, 2.32, and 1.57 is
\[ \frac{6.47 + 2.32 + 1.57}{3} = 3.453 \]
Let’s compute the mean of our larger dataset and plot it on our histogram.
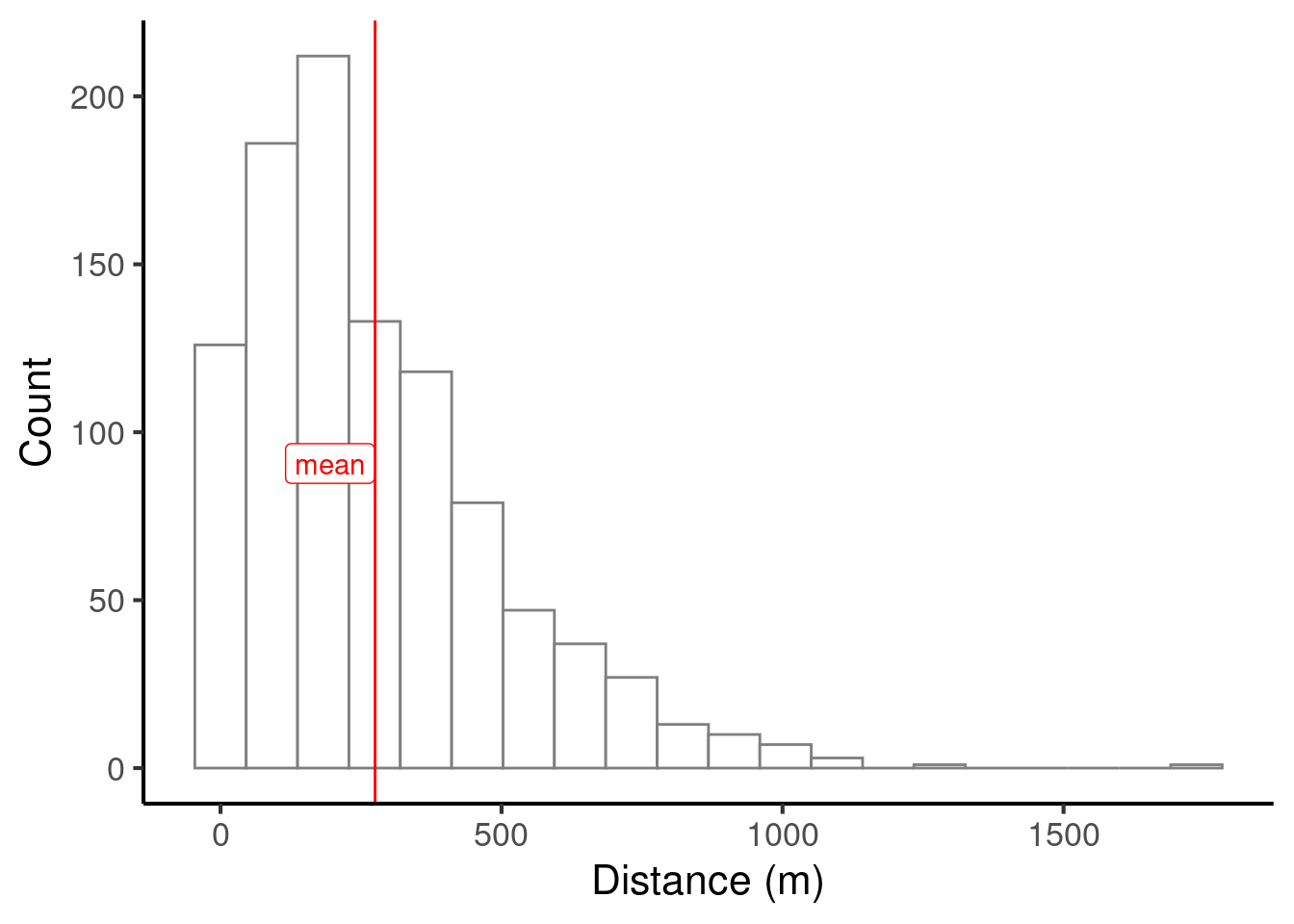
We can compute the mean in R with code like the following:
24.1.1.2 Median
The median is computed as follows: we rank the data points in numeric order, and then take the middle data point. For example, suppose that we want to compute the median of the following numbers:
\[ 5, 2.5, 8.3, 7, 1.2 \]
We first arrange them in ascending order:
\[ 1.2, 2.5, 5, 7, 8.3 \]
We then select the middle number:
\[ 1.2, 2.5, \mathbf{5}, 7, 8.3 \]
So, our median will be 5.
If we have an odd number of values, there will be exactly one number in the middle. If we have an even number of values, there will be exactly two numbers in the middle. In this case, we take the two middle values and average them to get the median.
Let’s add the median to our histogram:
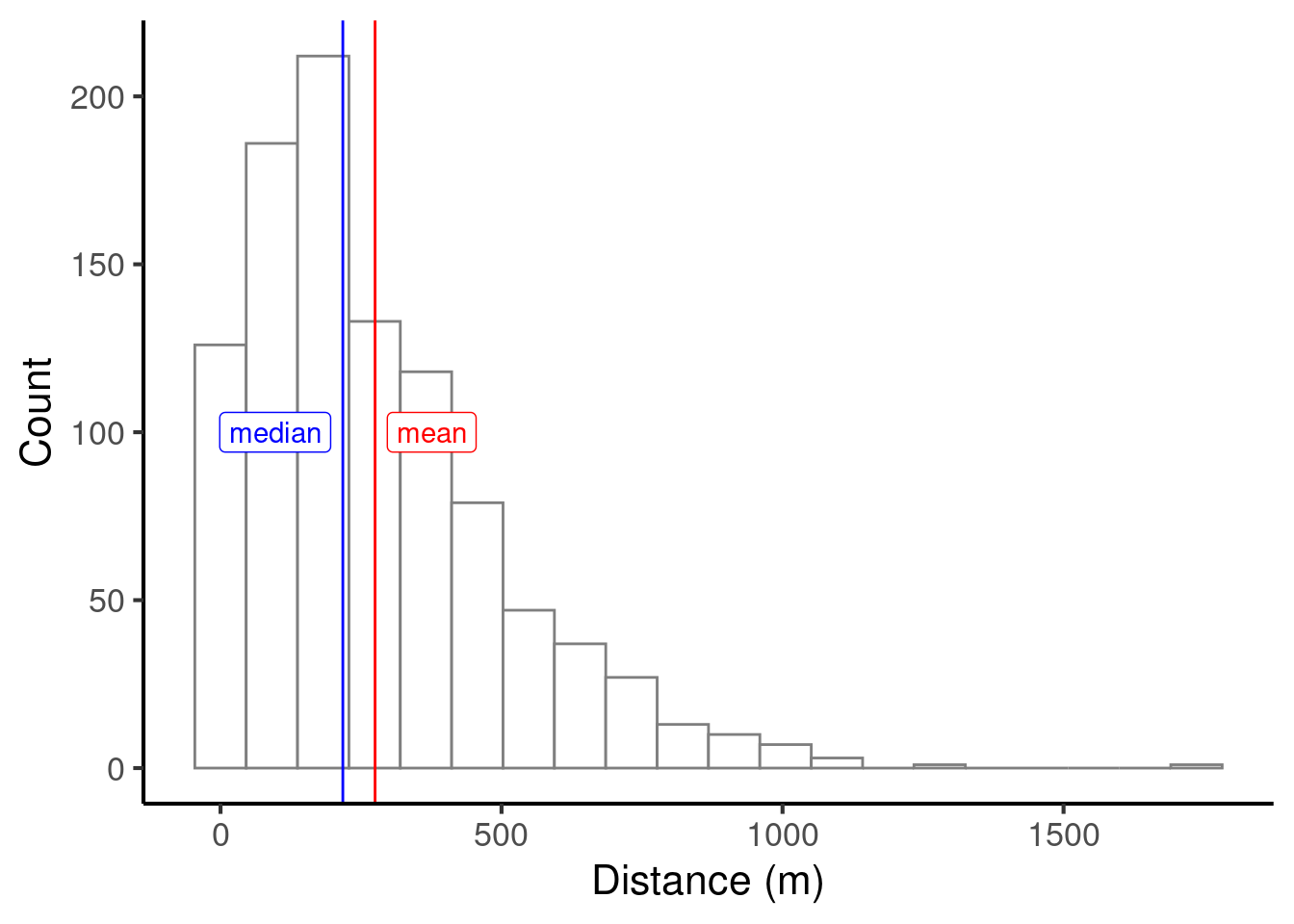
In this example the median is significantly smaller than the median. This is commonly the case with skewed distributions. Skewed distributions can often be found in socioeconomic studies; for example, income distributions tend to have the majority of incomes bunched towards the bottom of the distribution, contrasting with a smaller number of much higher incomes towards the top of the distribution. This yields the paradoxical situation that the ‘average’ person earns less than the average income.
We can compute the median in R with code like the following:
24.1.1.3 Mode
The mode is only properly defined for variables that can only take a finite number of values. It is defined as the value that is observed most often in the dataset. For example, suppose we record the following dataset tabulating the number of cars owned by different families:
We can plot the counts of each number in a bar plot:
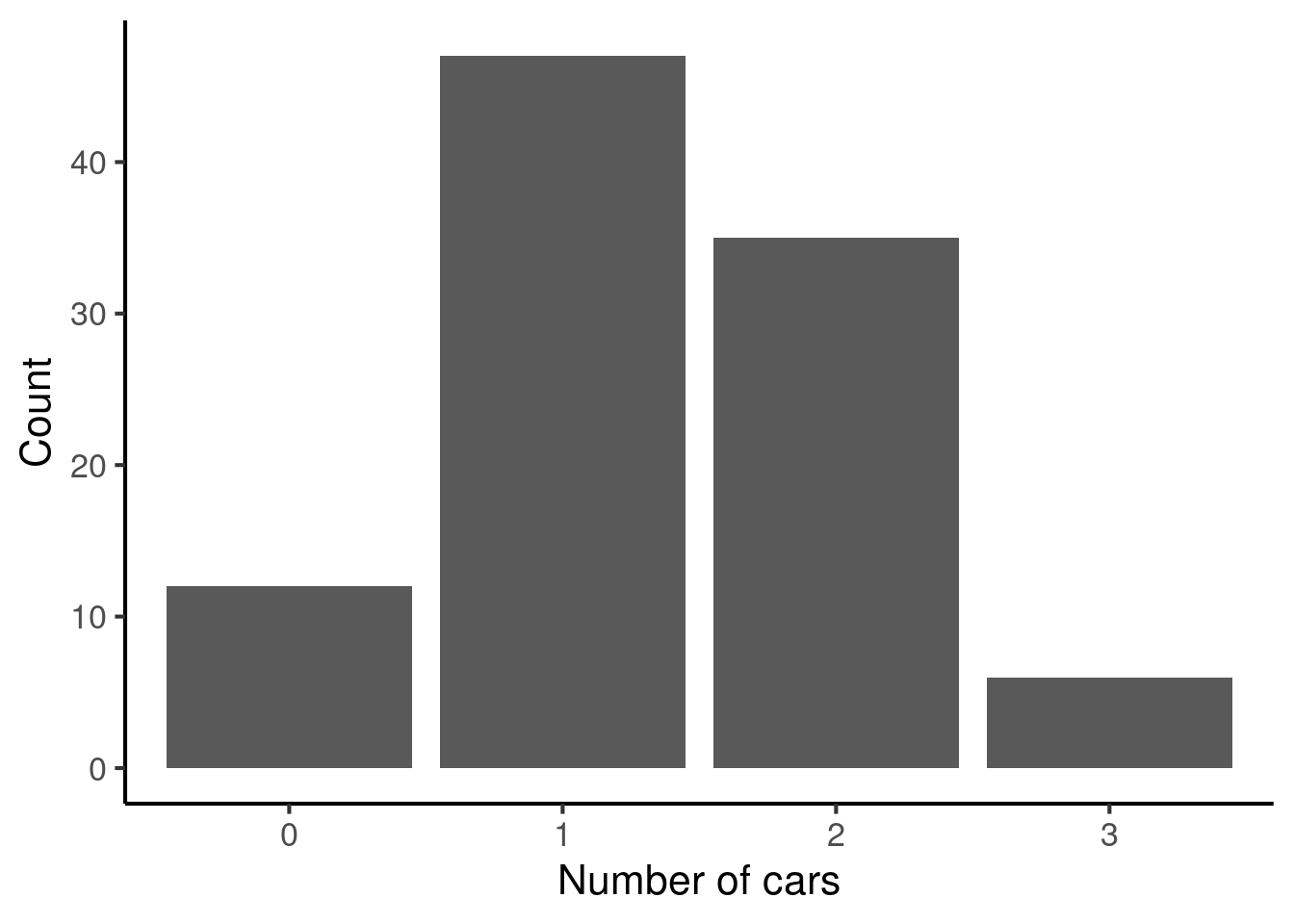
The mode then corresponds to the highest bar, 1.
24.1.2 Spread
Alongside centrality, it is useful to characterise the spread of our dataset. There are various relevant statistics here, including the range, standard deviation, and interquartile range.
24.1.2.1 Range
The range simply corresponds to the difference between the highest and the lowest values observed in the dataset. Suppose we have the following dataset:
\[ 5, 3, 2, 4, 3 \] The minimum value is 2, and the maximum value is 5, so the range is 3.
The range is often described as an unreliable statistic because it is highly sensitive to outliers, that is, rare extreme values in the distribution. The following two statistics are however less sensitive to such outliers.
24.1.2.2 Standard deviation
The standard deviation can be informally understood as the average distance of each observation from the mean. We can compute it in R using code like the following:
The mathematical definition of standard deviation has some subtleties, though.
The ‘average’ here is computed by taking the ‘root mean square’ (i.e., taking the distances from the mean, squaring them, adding them, then taking the square root).
By default, we compute what is called the ‘sample standard deviation’, which has a built-in adjustment factor to account for uncertainty in the mean. The result is that the definition of standard deviation has \(n-1\) in the denominator (the lower part of the fraction) rather than \(n\).
The mathematical definition of the standard deviation is then:
\[ s = \sqrt{\frac{\sum_{i=1}^{N}(x_i - \bar{x}) ^ 2}{N-1}} \]
Here \(x_i\) refers to the \(i\)th value in the dataset, and \(\bar{x}\) refers to the mean value in the dataset. The sigma notation ()
If you are unfamiliar with this kind of mathematical notation, you may wish to have a look at Section 27.3.3.4. Don’t worry too much, though: this mathematical definition is not required for the Cambridge undergraduate courses, and you are unlikely to need to worry about it in most situations.
24.1.2.3 Interquartile range
The interquartile range is another measure of spread. It is based on the concept of percentiles. The x-th percentile of a given dataset is the value below which x% of the sample falls. For example, the 25th percentile is the value below which 25% of the sample falls. We can compute percentiles in R with code like the following:
x <- c(3, 6, 4, 3, 2, 2, 2, 3, 5, 6, 4, 5, 4, 3, 2, 5)
quantile(x, probs = c(0.25, 0.5, 0.75))
#> 25% 50% 75%
#> 2.75 3.50 5.00The interquartile range is based on the 25th and 75th percentile:
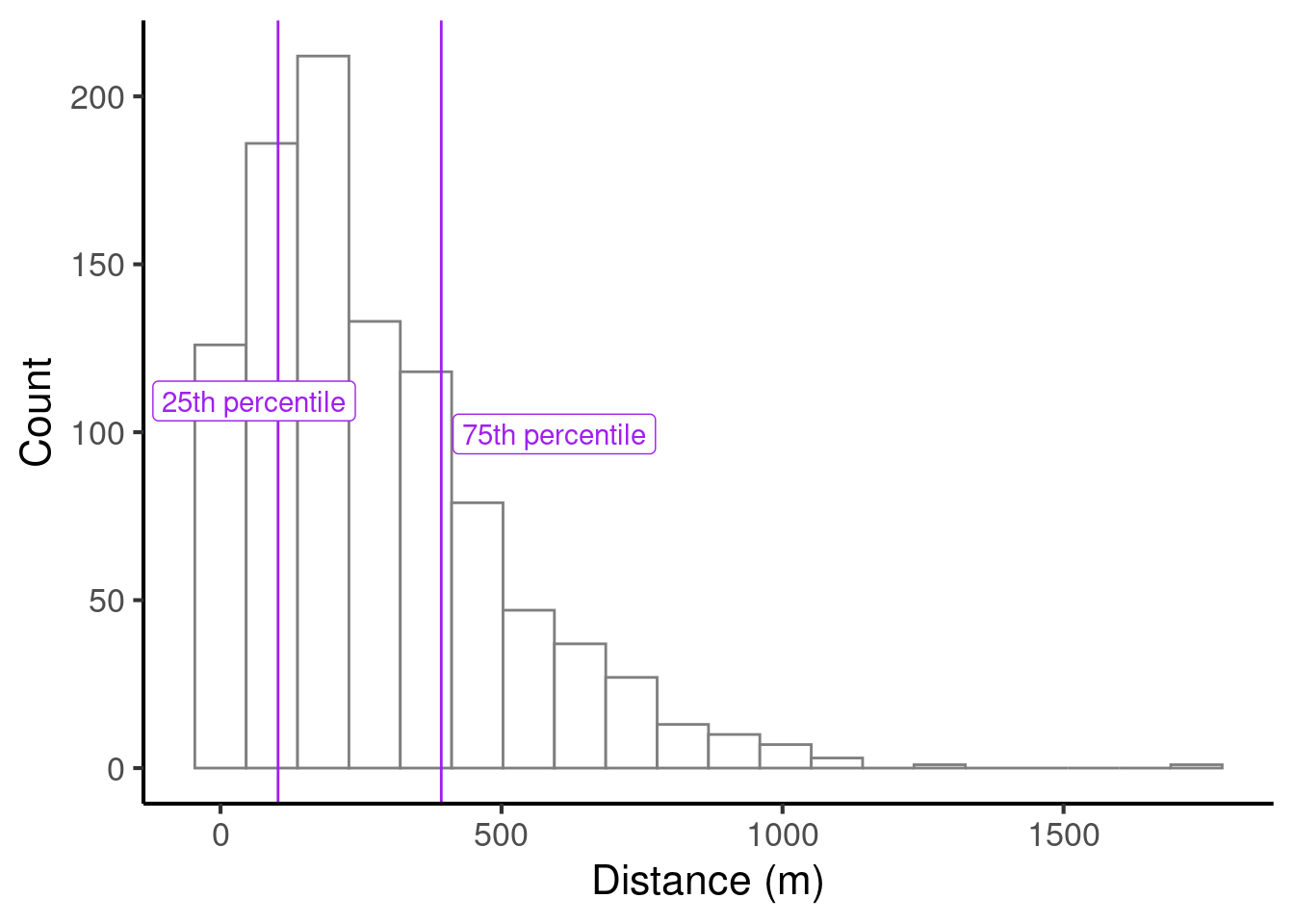
We compute the interquartile range as the difference between the 25th percentile and the 75th percentile. In this case, the interquartile range would be 290.4108358.
In R, we can compute the interquartile range using the IQR function:
24.1.2.4 Which spread statistic should I report?
In most practical contexts we tend to report the standard deviation. It is often useful to report the range as well. It is quite rare to report the interquartile range, but we sometimes report it if we believe that the dataset is highly skewed or contains many outliers.
24.2 Pairs of variables
24.2.1 Pairs of continuous variables
Often we want to understand how certain pairs of variables relate to each other. In Chapter 23 we learned various techniques for plotting such relationships. For example, we saw that pairs of continuous variables can be visualised using a scatter plot:
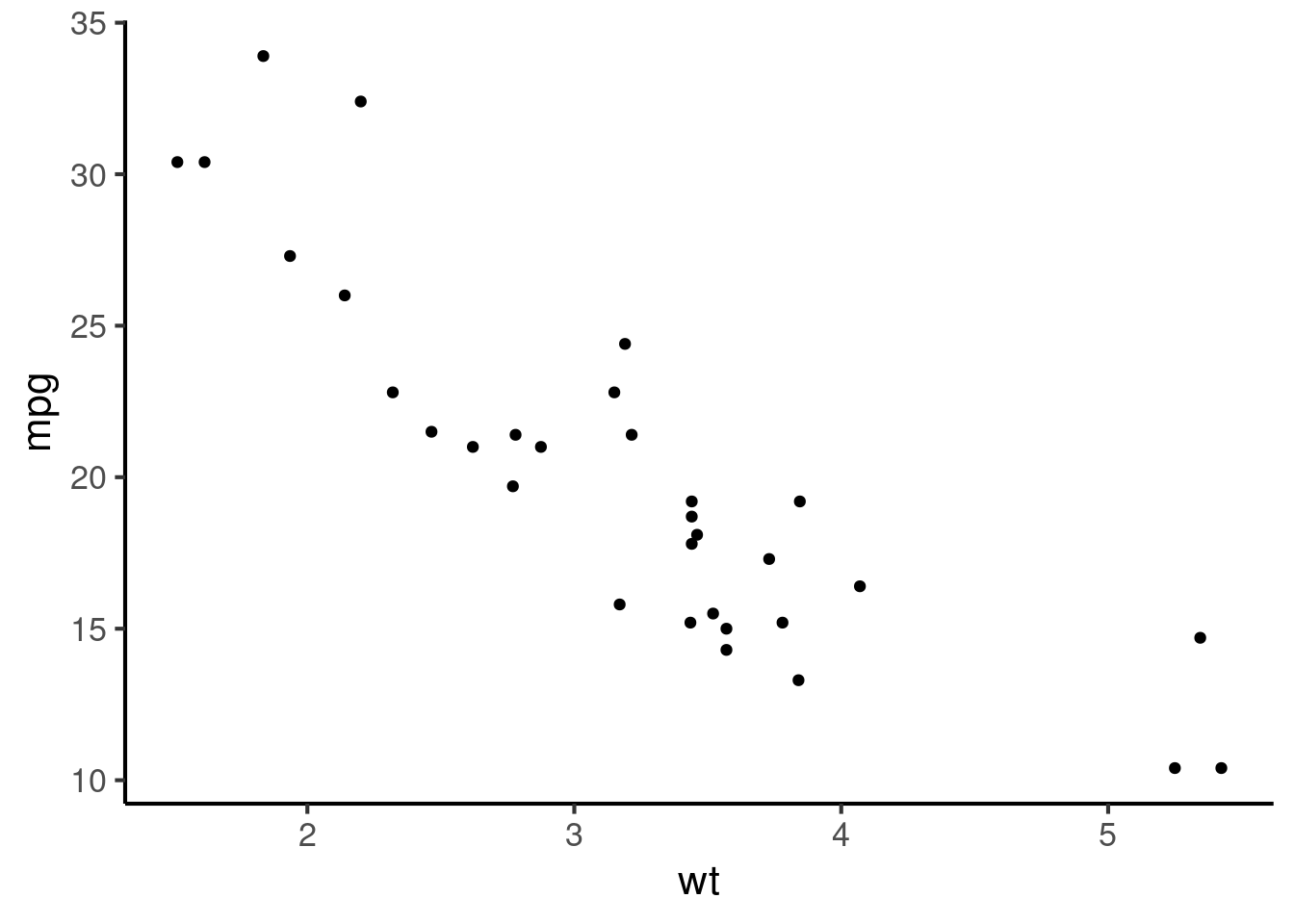
A key descriptive statistic in this context (two continuous variables) is the correlation coefficient. The correlation coefficient is a way of quantifying the strength of the relationship between two variables.
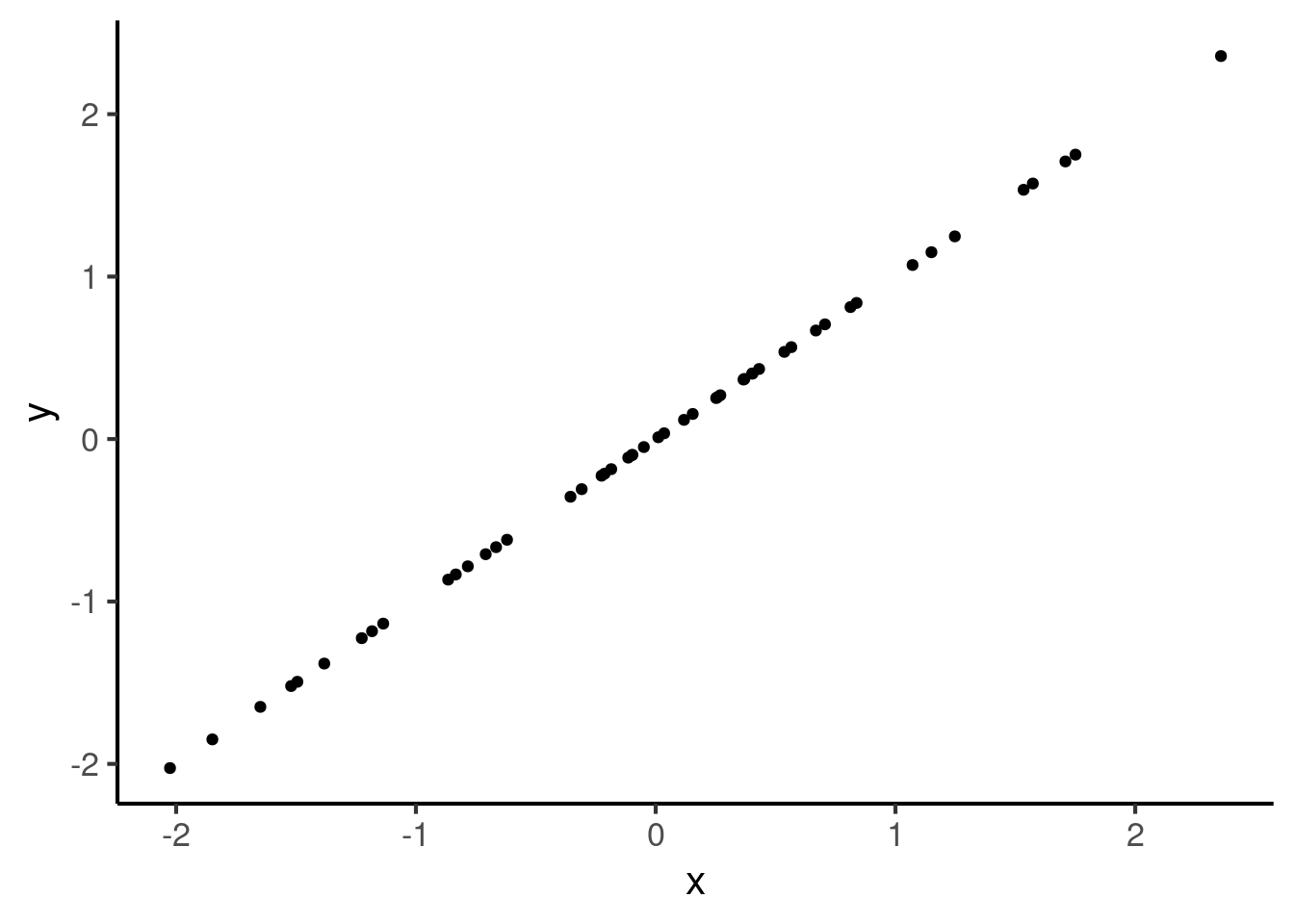
A correlation of 1 means a perfect positive correlation, where the relationship between the two variables is perfectly summarised by a straight line with a positive (i.e. ascending) gradient:
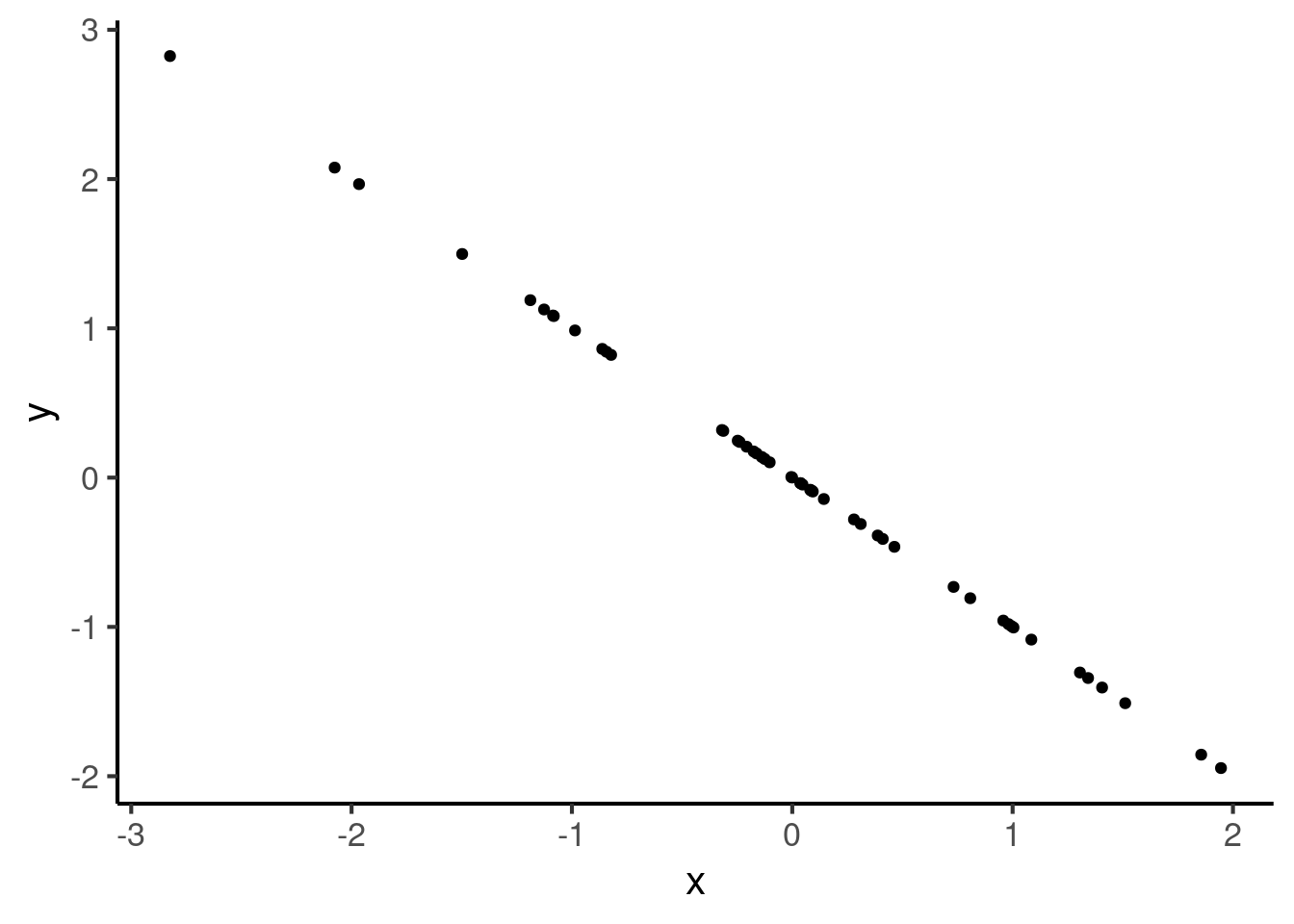
A correlation of -1 also means that the relationship is perfectly summarised by a straight line, but one with negative gradient:
These cases may be contrasted with a correlation of 0, which corresponds to the absence of a relationship:
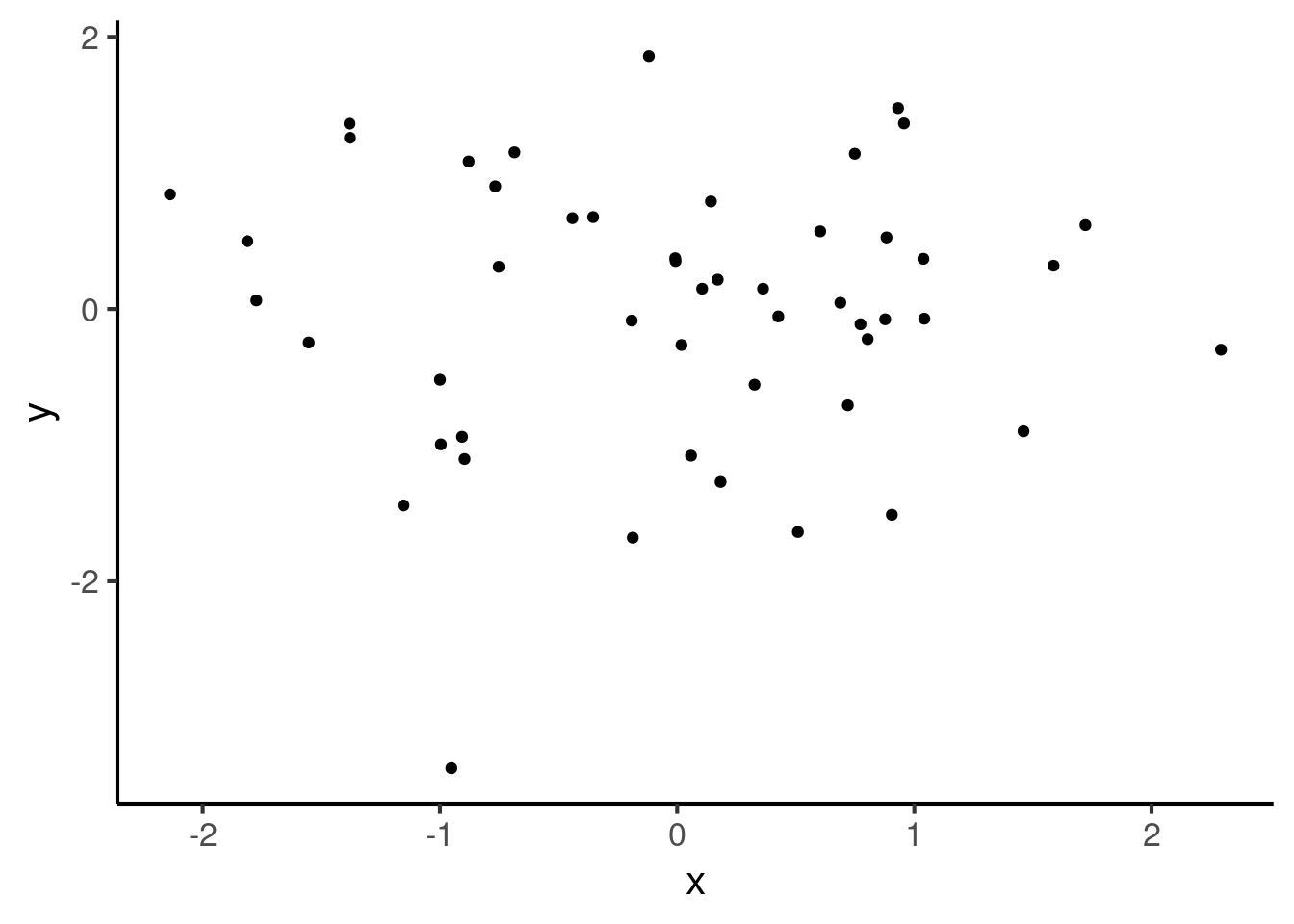
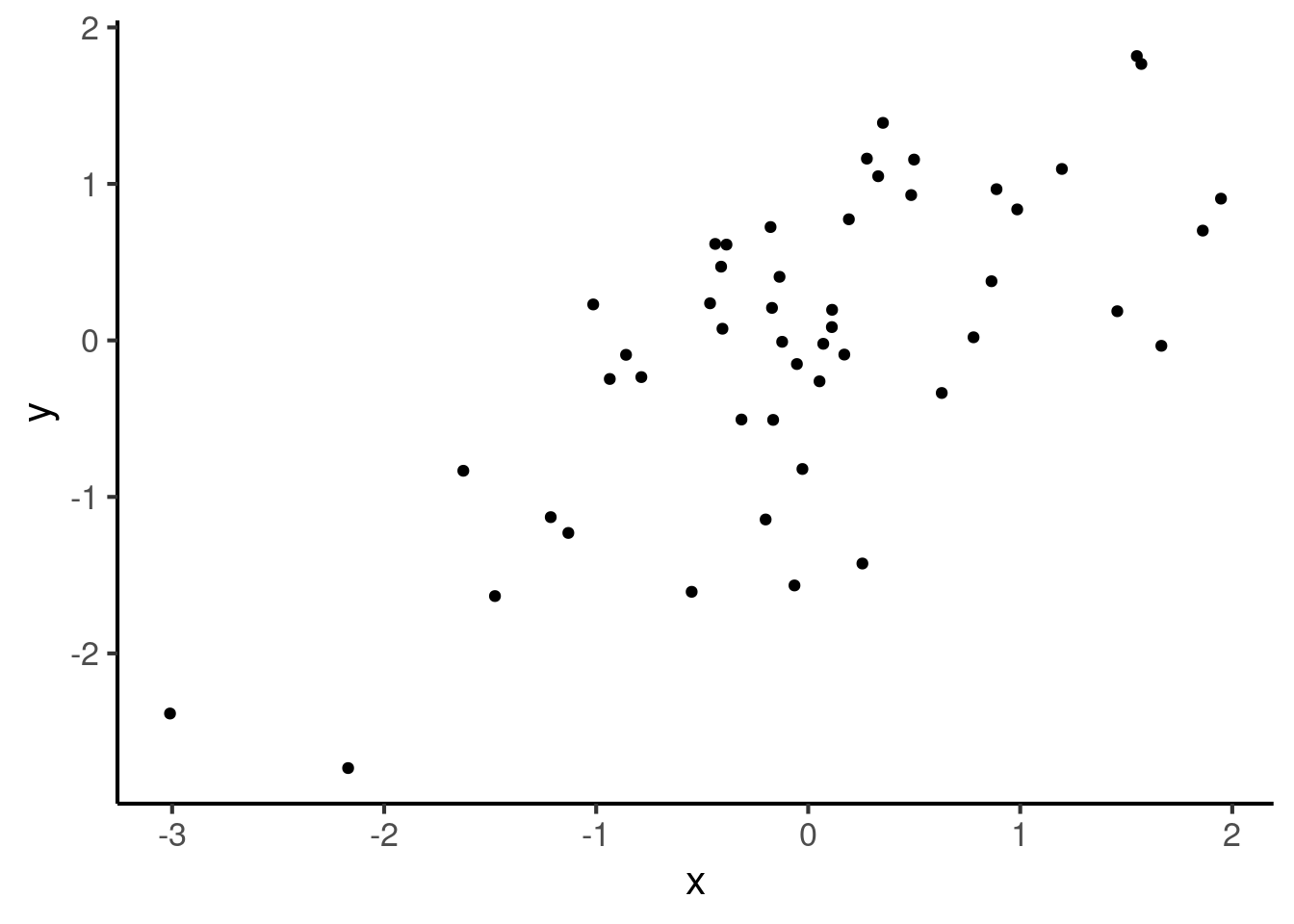
Intermediate numbers between these values then correspond to noisy relationships. In a noisy relationship, one variable gives some information about the other variable, but not enough to perfectly predict it. Here we have an example of a correlation of 0.7:
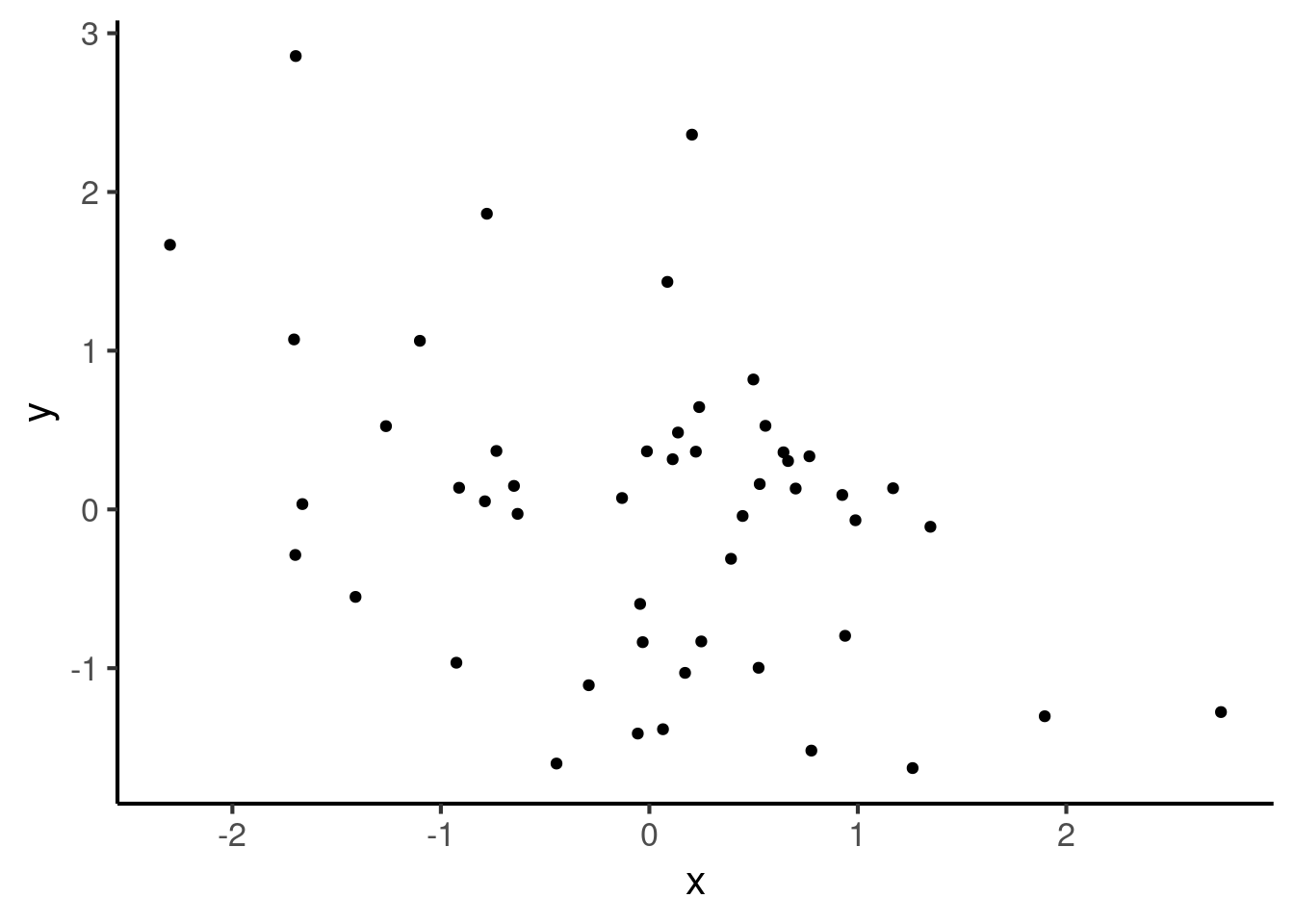
Here is a correlation of -0.4:
There are different types of correlation coefficients out there. The most common is the Pearson correlation coefficient, which is what we’ve been plotting just now. This is the default used by most statistical software. In R, you can compute the Pearson correlation coefficient as follows:
24.2.1.1 Outliers
A troublesome thing about the Pearson correlation coefficient is that it is rather sensitive to outliers (i.e. extreme data values). This will be illustrated with an example. Suppose we start with a dataset where the correlation coefficient is 0:
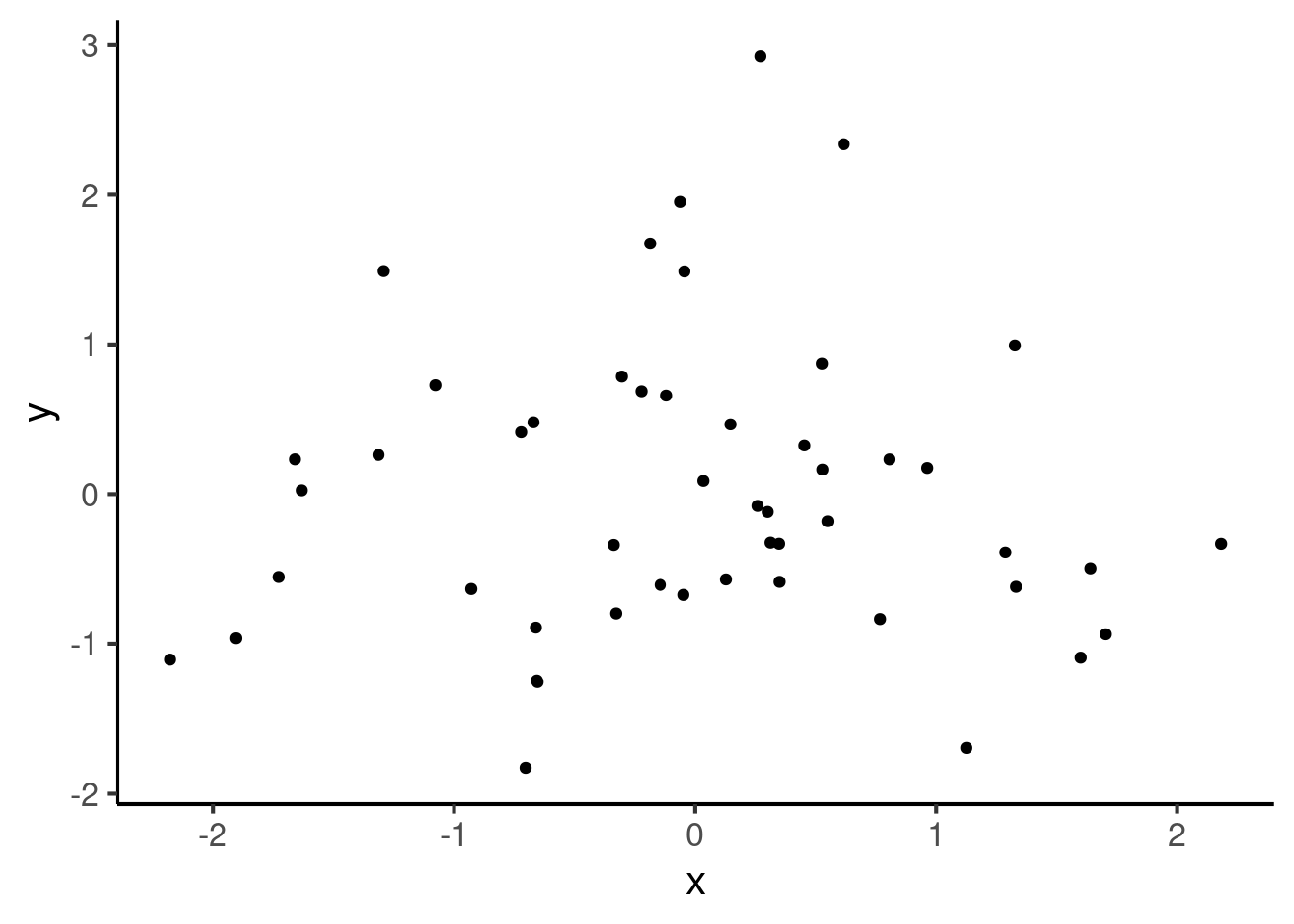
cor(x, y)
#> [1] 0.3015113Now let’s add one outlier to this dataset, with a large x value and a large y value.
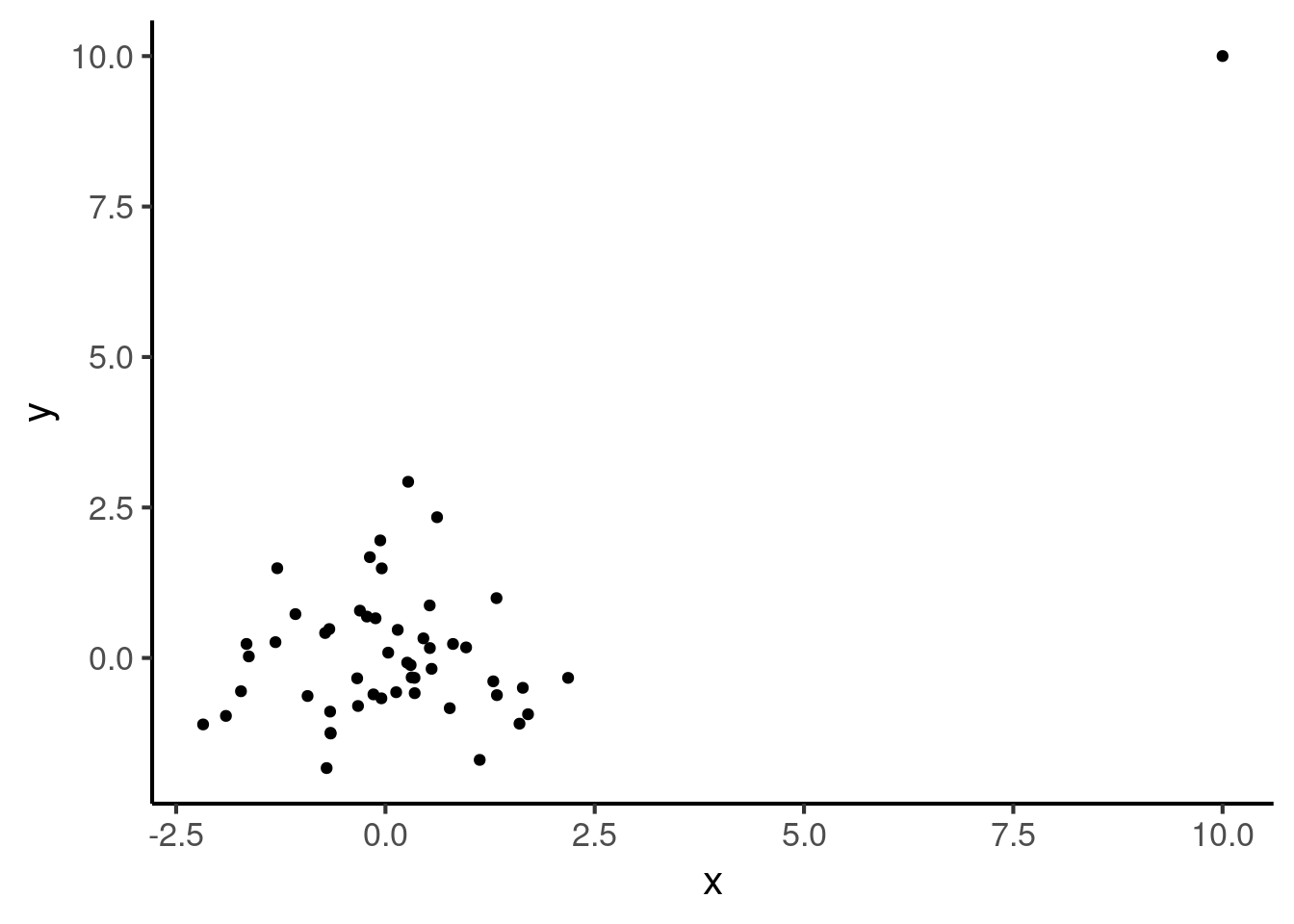
If we compute the correlation between these two variables, we find that it has now increased to a rather large number, despite the fact that the original dataset had no correlation at all:
cor(df2$x, df2$y)
#> [1] 0.6667556There are fortunately other types of correlation coefficient that are robust to these kinds of issues. These are called non-parametric correlation coefficients (this contrasts with the Pearson coefficient, which is a parametric coefficient). Two such coefficients are particularly popular: the Spearman and the Kendall correlation coefficients. These coefficients both also give numbers between -1 and 1. They are, however, much less sensitive to outliers. Let’s see what they return for our dataset:
cor(df2$x, df2$y, method = "spearman")
#> [1] 0.05411765
cor(df2$x, df2$y, method = "kendall")
#> [1] 0.03686275All else aside, many statisticians prefer the Pearson correlation coefficient because it has certain useful statistical properties. However, it is a good idea to use a non-parametric coefficient if one is worried about outliers.
24.2.1.2 Linearity
It is important to note that correlation coefficients only look for increasing or decreasing relationships. They do not look for more complex shapes. For example, the following curve illustrates a situation where \(y\) is perfectly predicted from \(x\), yet the correlation coefficient is 0:
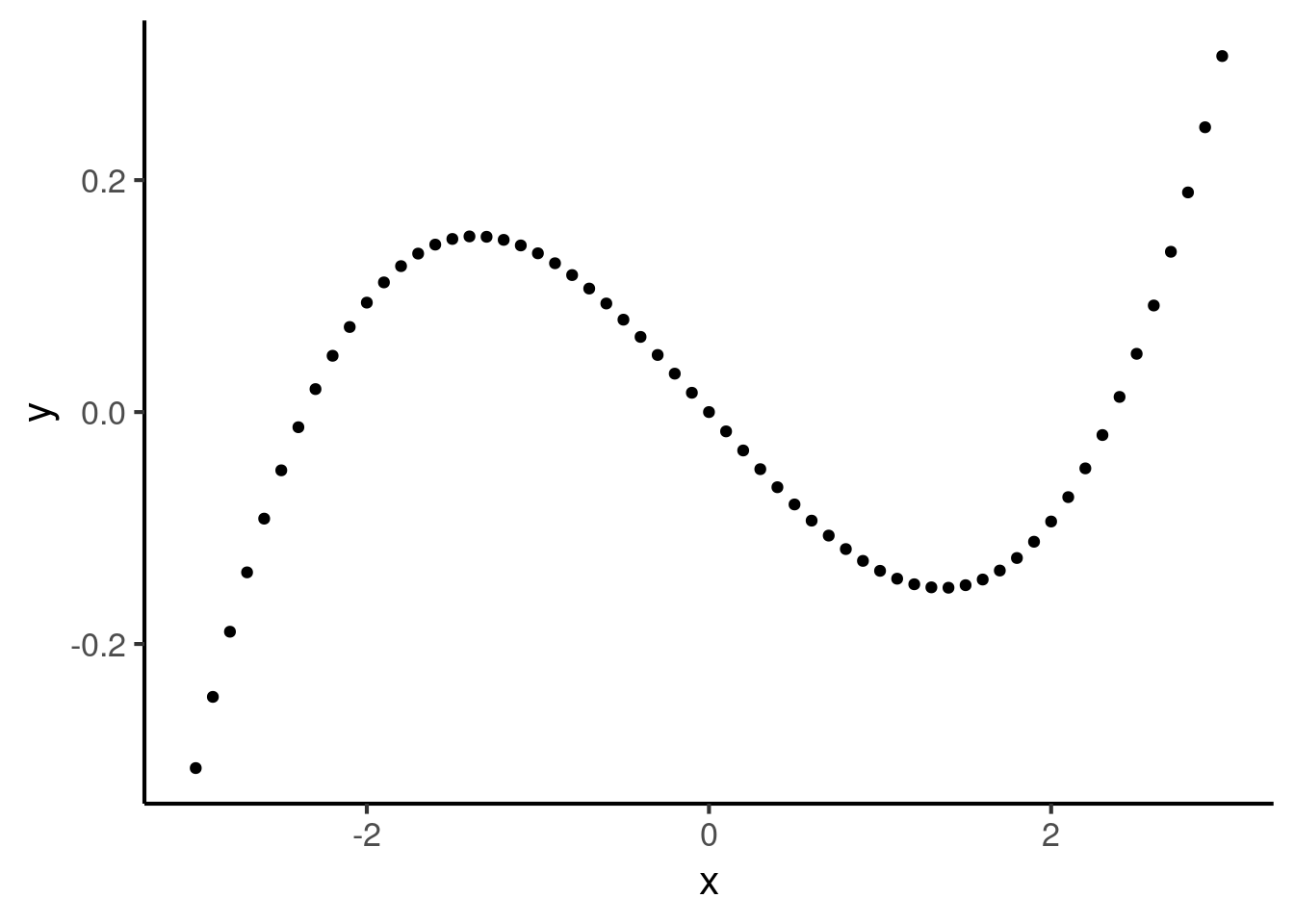
The Pearson correlation coefficient is particularly picky in that it looks specifically for straight lines (in statistics lingo: linear relationships). So, the following curve has a Pearson correlation coefficient less than 1:
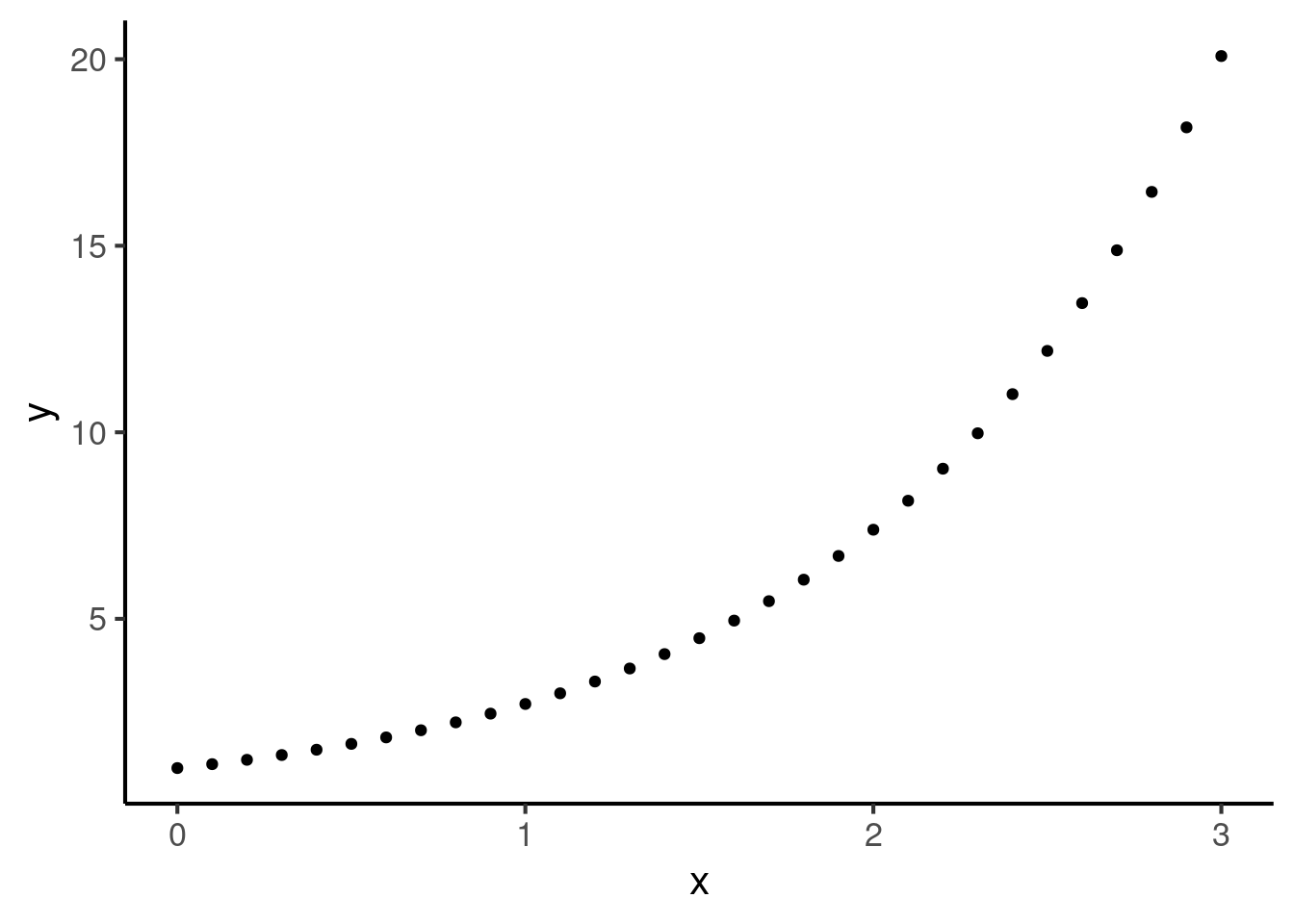
In contrast, the nonparametric correlation coefficients only look for monotonic (i.e. always increasing or always decreasing) relationships. This means they return 1 for the above plot.
cor(df$x, df$y, method = "spearman") %>% round(3)
#> [1] 1
cor(df$x, df$y, method = "kendall") %>% round(3)
#> [1] 1This is because nonparametric statistics only look at the order of points, not their precise values.